

How to Teach Data Literacy
How to Teach Data Literacy
A primer on how to educate non-STEM students about data and its uses

Data Literacy is the literacy of the 21st Century. Both societal and individual progress in the coming decade will depend on the ability to understand and manipulate data.
But, only a small subset of the general population possesses this ability. Check the chart below. In the US, around 20% of college students graduate from STEM fields (this number has risen by around 8% since).
If we assume that these students are data literate (to some minimal degree, at least), what about the rest?
How can they achieve data literacy?

The solution is fairly simple, as far as the educational curricula in non-stem fields are concerned. Data Literacy is an instance of Critical Thinking, specifically its inductive reasoning component. It can be taught as a required course to freshmen and/or sophomores.
There are two possible routes to this.
Data Literacy as Part of Critical Thinking
One route is to make Data Literacy a part of the existing Critical Thinking courses at the 100 level.
Most college students are required to take a course in Critical Thinking during their (typical) 4-year college education. Data Literacy skills can be integrated into these courses (in cases where they’re not already) with only a few tweaks to the syllabi.
Here’s a small example of how that can be done.
Most Critical Thinking classes start by teaching students argument-making fundamentals. Statements are the basis of arguments (both deductive and inductive). For example, here’s a simple deductive argument:
Statement 1: All dogs are cute.
Statement 2: Fluffy is a dog.
Statement 3: Fluffy is cute.
To understand how Statement 3 follows from Statements 1 and 2, students need to understand that statements are sentences with a truth value, i.e., sentences that can be either true or false.
This offers a great opportunity to teach students that Data are instances not dissimilar to statements. They are small ‘truths’ we access and use to generate some other claims on their basis.
Of course, Data analyses involve inductive reasoning rather than deductive, so the transition from one to the other offers another opportunity to teach them how reasoning with Data works.
For example, let’s transform the ‘Fluffy’ deductive argument into an inductive one:
Statement 1: Mickey, Dickey, Baldy, Hairy, Dotty, Lotty, and Spotty are all dogs.
Statement 2: Mickey, Dickey, Baldy, Dotty, Lotty, and Spotty are cute.
Statement 3: Fluffy is a dog too.
Statement 4: Fluffy is probably cute.
In this case, Statement 4 is also arrived at by building and combining Statements 1, 2, and 3, but the truth of Statement 4 is not guaranteed here. This provides an opportunity to teach students what Data features are and how we can use them to predict labels of some future instances of a similar kind.
This is a great place to teach them Data analysis is not a fool-proof and certain activity. There will always be a chance that the conclusion is not true, but if we skillfully deploy some strategies (like smart sampling, for example) we can minimize that chance as much as possible.

Image source: https://danielmiessler.com/blog/the-difference-between-deductive-and-inductive-reasoning/
Data Literacy as a Standalone Course
The second route is to create a standalone Data Literacy course at a slightly higher level (I suggest 200-level).
This course can be framed in terms of three philosophical areas that would serve as placeholders for students’ progress in understanding the conceptual background of Data-based reasoning.
Ontology
First, students should be taught about the ontological basis of Data. Ontology is a philosophical discipline that interrogates the concepts of existence and reality.
They should learn first what counts as Data, where and how are Data found (generated), but also what are the different types of Data in existence, both simple (think strings, numbers, categories, booleans…etc.) and complex (think lists, dictionaries, data frames…etc.).
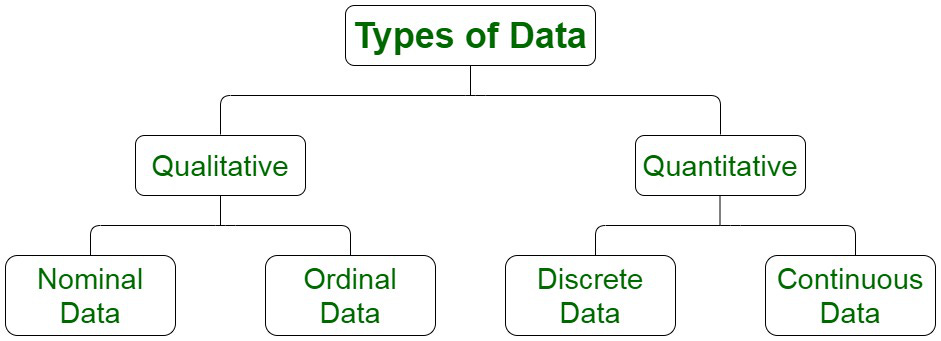
Image source: https://www.geeksforgeeks.org/explain-different-types-of-data-in-statistics/
Epistemology
Second, they should be taught about the epistemological basis of Data manipulation. Epistemology is a philosophical discipline that interrogates different types of knowledge and strategies of knowing.
Students could learn about data collection, data analysis, and prediction. Here’s where they could be taught about different statistical techniques (without the computational nitty-gritty), Machine Learning, and other similar methods or systems.
I’ll go out on a limb and suggest that we teach non-STEM students the basics of computer programming too, and the epistemological framework is the best place for that. After all, programming involves data (creation and) manipulation.
The aim of this would not be to make them all programmers but to help them understand the basic techniques of Data manipulation. Python (or some other open-source language) would be the best for this.
 - Wikipedia")
Ethics
Finally, they should learn about the ethical aspects of Data-based reasoning. We could teach them about the ethical status of Data collection, analysis, prediction, data and algorithm bias, and broader social consequences of Data-driven industries.
I don’t think any of this sounds too complicating, nor something that most educators with a Ph.D. in social sciences and/or philosophy would find impossible to deliver.

Image source: https://www.analyticsvidhya.com/blog/2021/03/fighting-data-bias-everyones-responsibility/
Finally,
I will be teaching such a course in Spring 2023 and will be happy to share my experiences and connect with folks who will attempt the same.
Feel free to connect with me via Twitter (@think___y) or email (eldar.sarajlic@gmail.com).